背景
最近由于有一次重大的线上活动,组织了对系统的进行压测,有一个场景的是用户提交一个问题的答案, 然后系统进行简单的业务判断后,把数据插入mangodb.
压测开始是蛮正常的, tps 稳定在 2000左右, 但是压半个小时候,突然的应用不响应,cpu 100%, 不停的进行gc
通过 dump 内存下来用 mat 内存分析工具分析如下
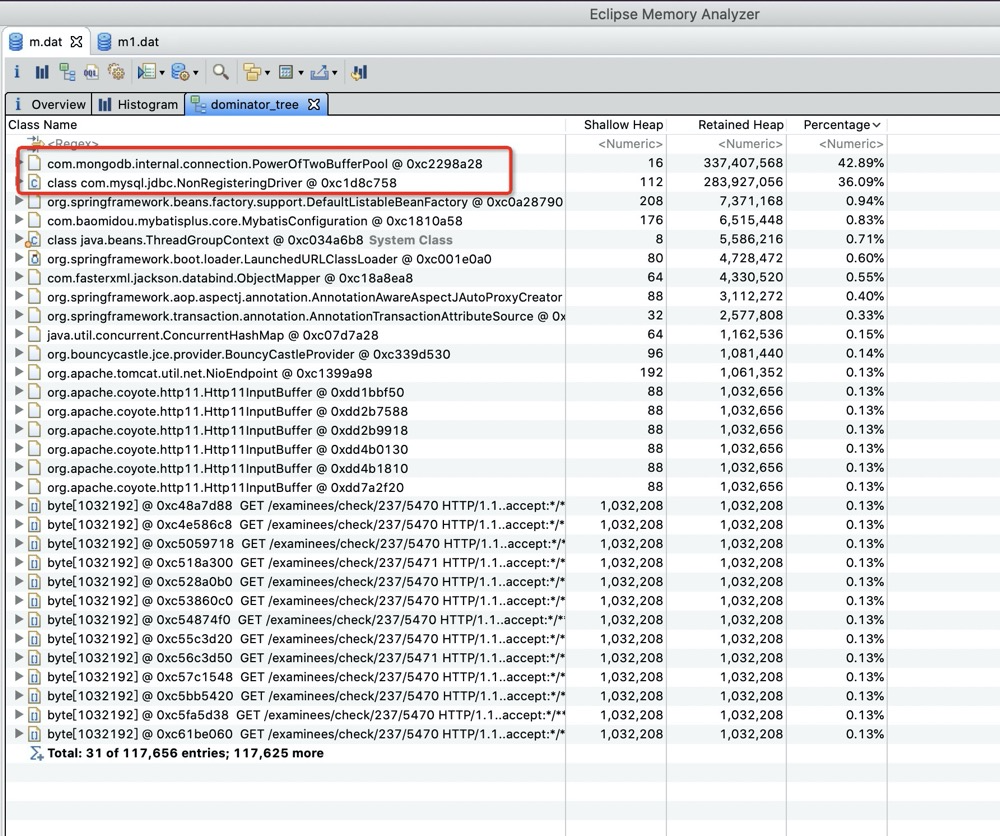
com.mongodb.internal.connection.PowerOfTwoBufferPool 有大量的buff对象
com.mysql.jdbc.NonRegisteringDriver 内也有5000多个
com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference
对象.
很明显的是由于这两个对象没有办法被gc回收而照成的不停的产生老年代的fullgc.
根据查找治疗得知 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 是mysql jdbc 驱动里面的类,用于追踪 创建的连接,本身是一个虚引用
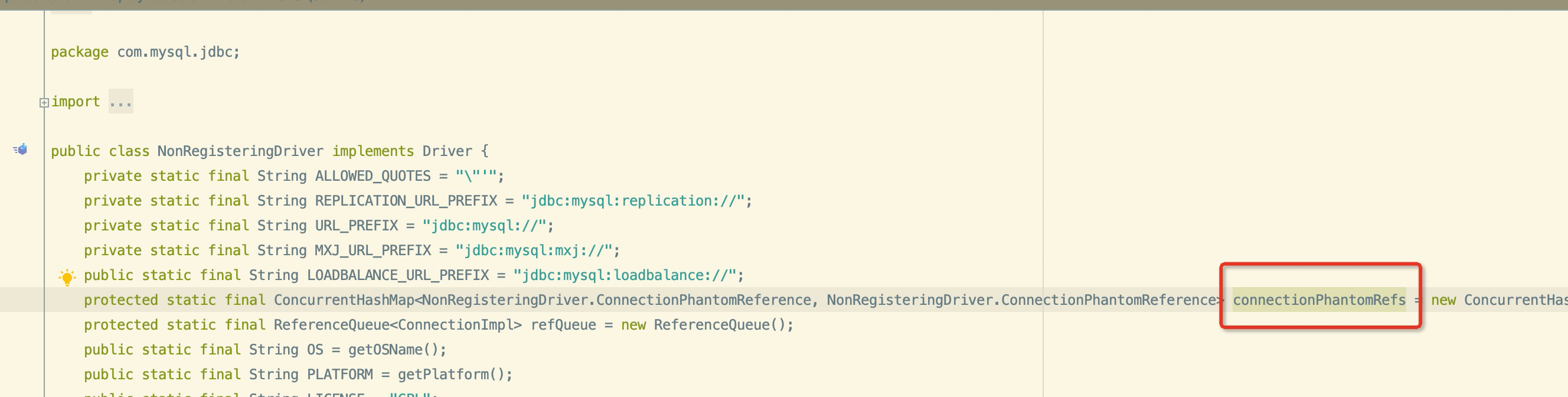
但是,本身jdk驱动是有开始一个新线程来进行,这个连接引用对象的回收的.
AbandonedConnectionCleanupThread 由这个线程类进行引用包装类的 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 的回收.
按道理来说我们应用是使用连接池的,不能可能创建出这么多废弃了连接,
通过检查配置后发现,我们使用的 HikariDataSource 连接池 max-lifetime 配置成了 3000 , 照成不停的销毁和创建连接. 通过调整 连接的最大生存时间, NonRegisteringDriver 比较大的问题解决
通过查找资料发现 PowerOfTwoBufferPool 是MongoDB 在主从环境上, 多节点通讯且异步写入时, 用于异步写入的缓存.
而我们最开始使用 spring-data-mongo时 只配置了uri连接信息,未配置其他的参数, 而mongo的默认使用的是异步写入, 在大量 数据插入时 PowerOfTwoBufferPool 就会变得特别的大.
通过添加如下配置
spring:
data:
mongodb:
connections-per-host: 80
min-connections-per-host: 20
threads-allowed-to-block-for-connection-multiplier: 4
write-number: 1
write-timeout: 2000
write-fsync: true
控制 mongodb 同步刷新, 且控制的超时时间
调整参数后再次压测, tps稳定在 2000tps左右 . 一个小时候再次打出堆dump
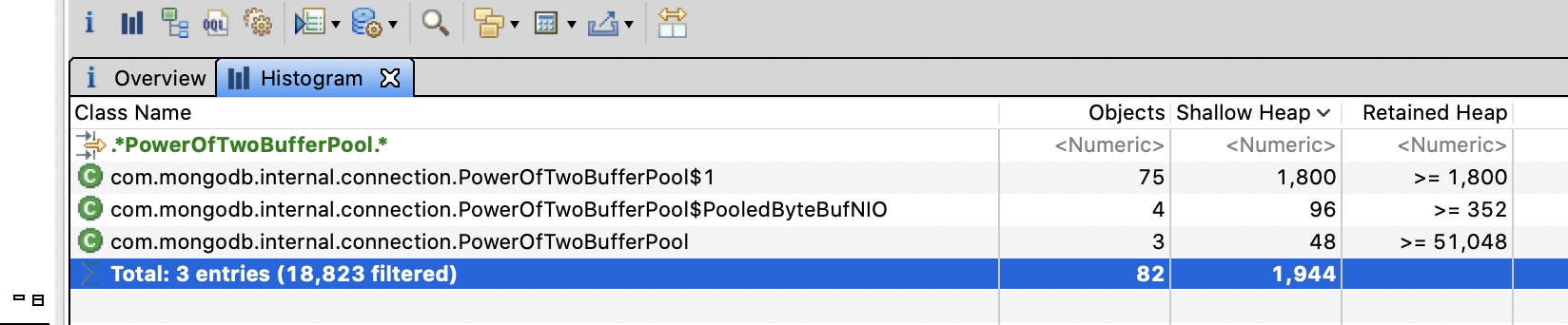

大小比较正常